

Техническая база знаний
 Документация к системе FBX
Документация к системе FBX- Абонентские приложения
- Абонентские устройства
- Каналы связи и протоколы
- Интеграция
- Каналы связи
- Коммутационные устройства
- Сервер телефонии
 FAQ
FAQ- Серверное оборудование
- Corosync + Pacemaker
- Термины и определения
- Настройка unbound - кэширующего днс сервера
- Требования к СПД
- Оборудование
Материал от эксперта

Corosync + Pacemaker
Портировать стаью для CentOS
http://www.alexlinux.com/asterisk-high-availability-cluster-with-pacemaker-on-centos-7/
https://raw.githubusercontent.com/ClusterLabs/resource-agents//master/heartbeat/asterisk
https://xakep.ru/2019/01/24/corosync-pacemaker/
https://github.com/ClusterLabs/pacemaker/blob/master/doc/pcs-crmsh-quick-ref.md
Общие сведения
В информационной сети кластер представлен тремя IP адресами:
- IP адрес управляющего интерфейса резервируемого сервера - используется для управления MASTER сервером в аварийном режиме работы кластера.
- IP адрес управляющего интерфейса резервирующего сервера - используется для управления SLAVE сервером в штатном режиме работы кластера.
- "Виртуальный IP адрес" кластера - используется всем клиентское оборудование (IP телефоны) для работы с системой вне зависимости от режима работы кластера. Данный адрес мигрирует в автоматическом режиме с одной системы на другую в зависимости от режима работы кластера.
Каждый сервер (MASTER и SLAVE) должен иметь своё уникальное имя в сети. Это имя определяется командой `hostname` в терминале ОС. На каждом сервере в файле /etc/hosts должна присутствовать одна и та же пара строк, каждая их которых содержит IP адрес сервера в кластере и его сетевое имя. Например, если сервер MASTER имеет в сети имя 'node-a' с управляющим интерфейсом '192.168.1.101', а SLAVE сервер имеет в сети имя 'node-b' с управляющим интерфейсом '192.168.1.102', то как на MASTER, так и на SLAVE сервере в файле /etc/hosts должны присутствовать следующие записи:
192.168.1.101 node-a 192.168.1.102 node-b
Для синхронизации работы кластера в сети, на узлах должен быть разрешен приём трафика, направляемый по multicast адресам. Ядро кластера будет рассылать пакеты в рамках multicast "сети" по порту 5405. Таким образом, необходимо заранее разрешить приём трафика по указанному порту, а также порту меньшем на единицу; а также разрешить обмен трафиком по протоколу IGMP (http://serverfault.com/questions/418634/secure-iptables-rules-for-corosync):
service fail2ban stop iptables -I INPUT -p igmp -j ACCEPT iptables -I INPUT -m addrtype --dst-type MULTICAST -j ACCEPT iptables -I INPUT -p udp -m multiport --dports 5404,5405 -j ACCEPT service iptables save service fail2ban start
Установка и настройка ядра кластеризации
Перед началом установки необходимо настроить окружение ОС. В частности,
В качестве ядра сервиса кластеризации будем использовать Corosync + Pacemaker. На момент написано документации, в репозитории CentOS присутствовали следующие версии пакетов:
- corosync 1.4.7-2.el6
- pacemaker 1.1.12-8.el6_7.2
К сожалению, в CentOS по-умолчанию не доступен crmsh, поэтому его нужно скачивать из репозитория OpenSUSE. После того как crmsh будет установлен, репозиторий SUSE лучше отключить:
yum -y install pacemaker corosync cd /etc/yum.repos.d/ wget http://download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-6/network:ha-clustering:Stable.repo yum -y install crmsh sed -i 's/enabled=1/enabled=0/g' /etc/yum.repos.d/network:ha-clustering:Stable.repo На CentOS 7 crmsh не устанавливается, так как требует python младшей версии, чем есть в репозитории CentOS, поэтому ставим pcs yum -y install pcs
Задаём переменные окружения, которые будут использоваться при дальнейшей настройке. Обращаю внимание, что переменные будут использоваться только при настройке, в работе самого сервиса кластеризации используются значения заданных переменных:
export ais_port=5405 export ais_mcast=226.94.1.1
Далее необходимо задать адрес сети, в которой будет работать corosync. Это должен быть адрес сетевого интерфейса, который соединяет два сервера напрямую. Последний октет адреса должен отличаться. Получить адрес можно так (строка универсальна как для master, так и для slave сервера):
ip addr | grep "inet " | tail -n 1 | awk '{print $4}' | sed s/255/0/
Если в результате выполнения команды был отображен адрес сети, которая установлена между серверами напрямую, то вышеуказанную команду можно использовать для установки переменной:
export ais_addr=`ip addr | grep "inet " | tail -n 1 | awk '{print $4}' | sed s/255/0/`
Отобразить полученные значения переменных можно выполнив следующую команду:
env | grep ais_
Необходимо проверить полученный адрес сети ais_addr с реальный требуемым, т.к. в некоторых случая команда получения адреса сети возвращает не верный результат (например, для сети /22). Проверить адрес сети можно любым сетевым калькулятором, например тут: http://ip-calculator.ru/ Если адрес сети будет указан не верно, узлы не найдут друг друга в составе кластера.
Далее мы создам файл конфигурации Corosync:
cat <<EOF >/etc/corosync/corosync.conf
compatibility: whitetank
totem {
version: 2
secauth: off
threads: 0
interface {
ringnumber: 0
bindnetaddr: $ais_addr
mcastaddr: $ais_mcast
mcastport: $ais_port
ttl: 1
}
}
logging {
fileline: off
to_stderr: no
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
}
}
EOF
Необходимо разрешить сервису corosync работать с правами root. Для этого надо добавить в конфигурационный файл соответствующие строки, выполнив следующую команду:
cat <<END >>/etc/corosync/corosync.conf
aisexec {
user: root
group: root
}
END
Также необходимо указать, что corosync должен работать с Pacemaker-ом, но НЕ должен его запускать самостоятельно. Если файл /etc/corosync/service.d/pacemaker существует, то нужно убедиться, что в нём значение параметра ver: 1.
Если файл /etc/corosync/service.d/pacemaker отсутствует, то в конфигурационный файл /etc/corosync/corosync.conf, добавлением соответствующие параметры:
cat <<END >>/etc/corosync/corosync.conf
service {
# Load the Pacemaker Cluster Resource Manager
name: pacemaker
ver: 1
use_mgmtd: no
use_logd: no
}
END
Параметр ver может принимать значения:
- 0 - Сервис pacemaker запускает сервис corosync автоматически. Таким образом pacemaker добавлять в автозагрузку не нужно. Данный вариант использовать только для pacemaker-1.0 и младше.
- 1 - Сервис pacemaker необходимо запускать вручную (индивидуальным скриптом в init.d). Таким образом нужно pacemaker добавлять в автозагрузку. Данный вариант нужно использовать с pacemaker-1.1 и выше.
Еще раз повторюсь, указанная выше конфигурация для pacemaker может присутствовать в файле /etc/corosync/service.d/pacemaker. Необходимо избежать дублирования данных параметров.
Полученный конфигурационный файл можно смело копировать на вторую ноду (или выполнить все те же самые команды на втором узле).
После того как конфигурация присутствует на двух узлах, можно запустить Corosync и Pacemaker на MASTER сервере. Порядок в данном случае важен.
service corosync start service pacemaker start chkconfig corosync on chkconfig pacemaker on
Только после того, как сервисы будут запущены, необходимо выполнить те же самые команды на SLAVE сервере.
Проверить состояние работы кластера можно выполнив команду. Не имеет значения, на каком узле была выполнена команда.
crm status
В результате вывода оба узла должны быть помечены как ONLINE.
Настройка менеджера ресурсов
После того, как узлы увидели друг друга, можно переходить к этапу настройки менеджера ресурсов.
Общие параметры
В первую очередь, необходимо выключить опцию STONITH в конфигурации менеджера ресурсов. Для этого на любом сервере нужно выполнить команду в Linux.
crm configure property stonith-enabled=false crm configure property no-quorum-policy="ignore" crm configure property start-failure-is-fatal=false
Результат выполнения команды внесёт изменение в конфигурацию менеджера ресурсов как на MASTER, так и на SLAVE сервере автоматически.
Можно посмотреть текущую конфигурацию pacemaker, выполнив команду
crm configure show
В результате вывода должны быть строки со следующими значениями параметров:
property expected-quorum-votes="2" property stonith-enabled="false" property no-quorum-policy="ignore" property start-failure-is-fatal=false
Если эти параметры не присутствуют в конфигурации, их нужно добавить по аналогии с параметром STONITH выше. Но, на самом деле, в конфигурации по-умолчанию опции есть и ничего добавлять самому не нужно, однако их наличие очень важно.
Типы ресурсов
- lsb - это init скрипты. При описании ресурса LSB указываются только общие для всех ресурсов параметр.
- ocf - это скрипты ядра кластера. При описании указываются индивидуальные параметры для каждого ресурса. Набор параметров всегда разный. В интернете есть подробное описание параметров.
Структура ресурсов
В кластере ресурсы могут быть объединены в группы, между ресурсами могут быть установлены зависимости, порядок запуска и много чего еще. Ниже представлена схема для упрощенного понимания структуры объединения ресурсов кластера серверов телефонии на базе DRBD. Отображены не все ресурсы, но суть такая:
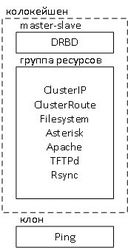
В виду того, что ресурсы и их объединения зависят друг от друга, необходимо соблюдать порядок их создания в конфигурации менеджера ресурсов. Для того чтобы понимать, что от чего зависит (опять же, не все связи отражены, но всё же), ниже представлена схема последовательности определения ресурсов в кластере.
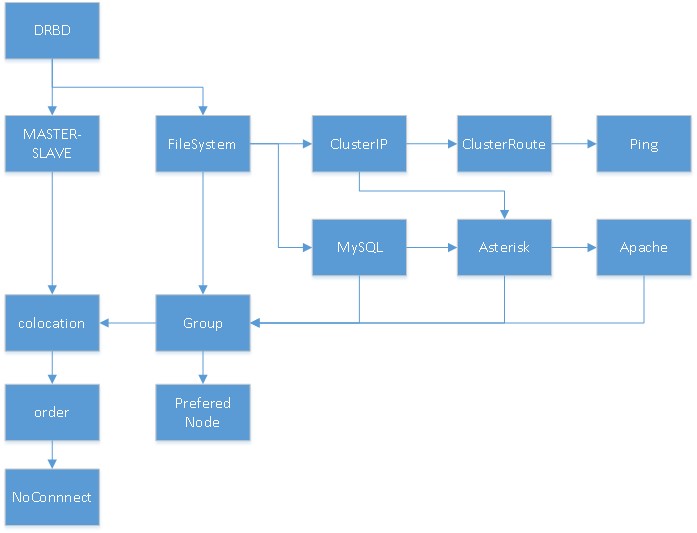
Ресурс DRBD
Если выполнять команды crm configure <что-то>, то они применяются на кластере моментально. Однако для ресурсов, использующих DRBD важна доступность самого DRBD, поэтому конфигураить их лучше всего в теневом инстансе. Для этого надо зайти в консоль управления кластером `crm` и выполнить команд для создания теневой конфигурации (позволит работать с конфигурацией до того, как будет применена в кластер):
crm(live)# cib new drbd INFO: drbd shadow CIB created crm(drbd)#
Изменение crm(live) на crm(drbd) говорит о том, что работа ведётся в теневом инстансе.
Далее необходимо описать ресурс `drbd_res` (имя ресурса) и конфигурацию `master_slave` (`drbd_master_slave` - имя конфигурации master_slave) для DRBD, после чего применить конфигурацию в `live` инстанс:
configure primitive drbd_res ocf:linbit:drbd params drbd_resource=disk1 op monitor interval=29s role=Master op monitor interval=31s role=Slave configure ms drbd_master_slave drbd_res meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true cib commit drbd
Здесь:
- drbd_res - имя ресурса кластера, которым мы будем оперировать в дальнейшем.
drbd_resource - указывает имя ресурса DRBD, который описан в соответствующем конфигурационном файле /etc/drbd.d/
Для конфигурации ресурса drbd используется ocf скрип, который обеспечивает переключение primary/secondary режимов сервиса DRBD узлов кластера в автоматическом режиме.
Конфигурация master-slave обеспечивает работу сервиса DRBD в состоянии primary только на одном узле в кластере.
Ресурс FileSystem
После того как ресурс DRBD определён, можно указать подключение раздела drbd к файловой системе, для этого будет также использоваться соответствующий ocf скрипт. Кстати, данный ocf скрипт можно использовать не только для раздела drbd, но и для любого другого раздела.
Подключение раздела к файловой системе тесно зависит от того, какой узел на текущий момент является DRBD primary. Поэтому необходимо создать привязку ресурса filesystem к активному DRBD узлу. Если этого не сделать, ресурс drbd может быть активен на одном узле, а примонтирование раздела к файловой системы произойдёт на другом узле, что привёдет к ошибке. Поэтому необходимо также в теневом инстансе создать описание ресурсов и конфигурации, а затем применить инстанс в текущую конфигурацию кластера.
cib new fs configure primitive fs_res ocf:heartbeat:Filesystem params device=/dev/drbd1 directory=/mnt/drbd fstype=ext4
Здесь
- fs_res - название ресурса подключение раздела DRBD к файловой системе;
- device - указывает на блочный девайс раздела drbd
- directory - указывает на директорию, куда нужно монтировать раздел
- fstype - указывает на тип файловой системы, которой размечен раздел drbd
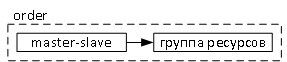
configure colocation fs_drbd_colo INFINITY: fs_res drbd_master_slave:Master configure order fs_after_drbd mandatory: drbd_master_slave:promote fs_res:start cib commit fs
Конфигурация расположения ресурса вместе с другим ресурсом тесно связана с конфигурацией описания порядка загрузки ресусов. Т.е. мало того, что ресурсы должны находится вместе (colocation), необходимо также указать, в каком порядке их следует запускать (order). Здесь:
fs_drbd_colo - название конфигурации colocaion;
drbd_master_slave:Master - состояние конфигурации master_slave равное Master, к которой привязывается расположение ресурса. ;
fs_after_drbd - название конфигурации order;
drbd_master_slave:promote - состояние конфигурции master_slave равное promote (i.e. the DRBD resource is promoted to master before the filesystem resource is started and any mount occurs);
fs_res:start - состояние ресурса start.
В данной конйигурации правило INFINITY и mandatory (говорят, тоже самое, что и INFINITY) указывает, что ресурсы должны располагаться на одном узле без исключения.
ВАЖНО: после описания конфигурации она была применена в текущую конфигурацию кластера.
Согласен, мы уже описали colocation и order правила, и включили сюда только ресурс filesystem, в то время как у нас должна быть группа ресурсов в том числе и последовательность запуска внутри группы. Но т.к. других ресурсов еще не описано, а конфигурация drbd неразрывно связана с конфигурацией файловой системы, мы описали правила расположения уже сейчас. В дальнейшем, когда мы опишем группу ресурсов и порядок загрузки ресурсов в группе, произойдёт автоматическая конвертация правил в конфигурции, таким образом мы сможем достичь последовательной загрузки ресрусов в зависимости от состояния кластера.
Ресурс Виртуального IP адреса
При переключении кластера из штатного режима функционирования в аварийный режим и обратно, между узлами должен мигрировать виртуальный IP адрес кластера, чтобы устройства в сети могли продолжать работать. Для этого необходимо описат соответствующий ресурс. Ресурс может быть описан двумя путями: через ocf (предпочтительней) в качестве alias и через lsb отдельным интерфейсом. Отдельный интерфейс менее желателен, т.к. сложнее контролировать доступность его подключения.
В качестве alias
Для создания виртуального IP адреса в качестве alias на существующем интерфейсе (предпочтительный вариант), необходимо добавит ocf ресурс IPaddr2, выполнив следующую команду:
crm configure primitive ClusterIP ocf:heartbeat:IPaddr2 params ip="192.168.1.100" cidr_netmask="24" nic="eth0"
Где обязательными параметрами кластера ресурса являются:
- ip - указывается выделенный виртуальный IP адрес кластера;
- cidr_netmask - маска подсети выделенного виртуального IP адреса кластера;
- nic - имя сетевого интерфейса, на котором указан должен быть создан alias.
Отдельным интерфейсом
На основе ресурса lsb
Не дописано!
Ресурс динамического маршрута
При переключении кластера можно также добавлять маршруты. В этом есть необходимость только в том случае, если статические маршруты, отличающиеся от маршрутов по-умолчанию, назначены на виртуальный интерфейс кластера, сеть которого отличается от сети управляющего интерфейса. Например, управляющая сеть имеет адрес 192.168.1.0/24, а сеть виртуального интерфейса имеет адрес 192.168.2.0/24. В противном случае, статические маршруты могут быть добавлены в конфигурацию сетевого интерфейса в операционной системе (см. настройка сетевых интерфейсов).
Для каждого маршрута нужно добавить отдельный ocf ресурс. Для это необходимо выполнить следующую команду:
crm configure primitive ClusterRoute ocf:heartbeat:Route params destination="default" gateway="192.168.1.1"
Где обязательными параметрами ресурса являются:
- destination - сеть или узел назначения, до которого прописывается маршрут. Может быть указан как 'default', так и конкретный IP адрес узла в сети, так и сеть в формате CIDR, т.е. с суффиксом /24, например.
- gateway - адрес шлюза, используемого для доступа к указанному назначению.
- device - сетевой интерфейс в системе (устройство), на котором должен быть прописан маршрут (не обязательный параметр)
- source - IP адрс сервера, с которого будут осуществляться подключения до указанного `destination` (не обязательный параметр, но указывается вместе с `gateway` или `device`)
- table - таблица, в которой должен присутствовать маршрут. Также может быть указан, но не является обязательным.
Ресурсы сервисов
Проще всего описываются ресурсы сервисов, для которых есть init скрипты. Достаточно для каждого сервиса прописать LSB ресурс. В частности, для кластера на DRBD мы описываем ресурсы MySQL, Asterisk, Apache. Однако, перед добавлением ресурсов в кластер необходимо остановить сервисы, иначе менеджер ресурсов в кластере выдаст ошибку при добавлении, из-за того, что сервис работает. Для этого, сначала производится остановка сервисов:
service httpd stop service asterisk stop service mysqld stop
Затем добавляются сами ресурсы. Для этого нужно выполнить по одной команде создания ресурса для каждого init скрипта:
crm configure primitive Apache lsb:httpd op monitor interval=60s timeout=30s on-fail=restart crm configure primitive Asterisk lsb:asterisk op monitor interval=5s timeout=30s on-fail=standby crm configure primitive MySQL lsb:mysqld op monitor interval="60s" timeout="60s"
После добавления ресурсов, сервисы сразу будут запущены.
Также могут быть добавлены ресурсы tftp и rsync:
crm configure primitive Rsyncd lsb:rsyncd op monitor interval="120s" timeout="60s" crm configure primitive TFTPd lsb:in.tftpd op monitor interval="120s" timeout="60s"
Создание группы ресурсов
После того как в конфигурации кластера определены ресурсы под все необходимые нам сервисы, ресурсы можно объединить в группы. Группа ресурсов - это комбинированое описание совместного расположения и порядка загрузки (colocation + order). Совместное расположение, понятно, определяется тем, какие ресурсы входят в группу. Порядок загрузки определяется тем, в какой последовательности они вписаны в группу. Итак, следует соблюдать следующую последовательность загрузки ресурсов:
- Виртуальный IP адрес кластера.
- Динамические маршруты.
- Файловые системы.
- MySQL
- Asterisk
- Apache
- TFTPd
- Rsyncd
- ...
Например, для кластера на DRBD достаточно прописать следующую конфигурацию группы:
crm configure group TelephonyGroup ClusterIP fs_res MySQL Asterisk Apache
В данном случае конфигурация группы будет называться TelephonyGroup (группа ресурсов для телефонии).
При выполнении данной команды, конфигурации order и colocation, созданные ранее на этапе описания ресурса файловой системы, в состав которых входят `fs_res`, будут автоматически заменены на конфигурации с `TelephonyGroup`, о чем сообщит система.
Ресурс проверки подключения
Во избежание рассинхронизации информации на узлах кластера, активный узел должен проверять, подключен ли он к сети, не потерял ли он физическое подключение. В случае, если узел понимает, что подключение к сети потеряно, он должен перейти в аварийный режим и остановить все активные ресурсы.
Ping
Для этого активный узел в должен периодически проверять, отвечают ли ему на ICMP запросы контрольные сетевые узлы. Данную операцию выполняет ocf ресурс ping. Однако ресурс сам по себе не обеспечивает переключение режима кластера или изменение статуса ресурса, зато ресурс изменяет значение переменной ядра кластера, на основе которой ядро может принять решение о текущем состоянии. Таким образом для определения, имеется ли физическое подключение узла к ЛВС, т.е. доступен ли контрольный узел в сети, необходимо определить следующий ресурс:
crm configure primitive ClusterPing ocf:pacemaker:ping params multiplier="111" host_list="192.168.1.1" name="ping_net" dampen="5s" op monitor interval="10s" timeout="60s"
Где
- multiplier - множетель переменной для каждого хоста.
- host_list - список контрольных узлов в сети, разделенных пробелом.
- name - имя переменной, которой будут задаваться значения в результате расчета, используя множетель.
- dampen - задержка перед внесением изменений в окружение кластера, указанная в секундах. Используется для того, чтобы ресурсы не прыгали между узлами, когда подключение теряется на очень маленькое время.
Данная конфигурация пингует хост. Каждый хост оценивается в 111 очков. Суммарное значение для каждой ноды хранится в переменной "ping_net". Эти значения можно и нужно использовать при определении места расположения ресурса.
Клон ресурса
Для того, чтобы данный ресурс был запущен одновременно на двух нодах, необходимо создать его клон. Клон задаётся соответствующим ресурсом:
crm configure clone Cloned-Ping ClusterPing
Таким образом будет создан ресурс Cloned-Ping, который будет запускать ClusterPing на обоих узлах вне зависимости от их состояния в кластере. Данее необходимо указать менеджеру ресурсов, как работать со статусом подключения на основе данных от ресурса ClusterPing.
Расположение и приоритизация узлов
Чаще всего необходимо запретить узлу запускать на себе ресурсы, если узел определил, что он не имеет связи с контрольным узлом в сети. Т.е. данная конфигурация применима, если доступность определяется только по одному контрольному узлу в сети. Для это необходимо определить ресурса, предписывающий размещение ресурсов на основании значения переменной "ping_net":
crm configure location NoConnectionNode ClusterIP rule -inf: not_defined ping_net or ping_net lte 0
Данный ресурс NoConnectionNode, предписывающий расположение, запрещает размещать ресурс ClusterIP на узле, где пинг меньше либо равен 0 (lte — less then or equal) или не запущен ресурс пинга. Достигается это за счет того, что узел с отсутствующим подключением получает ""минус бесконечность" очков".
Для того, чтобы ресурс вернулся на резервируемую ноду после возвращения подключения, необходимо определить ресурс, предписывающий расположение, устанавливающий 50 очков резервируемому узлу по-умолчанию.
crm configure location PreferedNode ClusterIP 50: node-a
Данный ресурс PreferedNode, предписывает расположение ресурса ClusterIP на узле 'node-a', устанавливая узлу node-a на 50 очков больше.
Необходимо дополнить статью описанием таймеров!
Более сложные правила работы с доступностью контрольных узлов можно почитать на соответствующих тематических сайтах (ссылки внизу).
Конечная конфигурация
Посмотреть конечную конфигурацию кластера можно выполнив команду:
crm configure show
В результате её исполнения, должна отобразиться текущая конфигурация, примерно следующая:
node msa-tstasterisk1 \
attributes standby=off
node msa-tstasterisk2 \
attributes standby=off
primitive Apache lsb:httpd \
op monitor interval=30s timeout=30s
primitive Asterisk lsb:asterisk \
op monitor interval=30s timeout=60s
primitive ClusterIP IPaddr2 \
params ip=192.168.35.77 cidr_netmask=24 nic=eth0
primitive ClusterPing ocf:pacemaker:ping \
params multiplier=111 host_list=192.168.35.1 name=ping_net dampen=5s \
op monitor interval=10s timeout=60s
primitive MySQL lsb:mysqld \
meta is-managed=true
primitive drbd_res ocf:linbit:drbd \
params drbd_resource=disk1 \
op monitor interval=29s role=Master \
op monitor interval=31s role=Slave
primitive fs_res Filesystem \
params device="/dev/drbd1" directory="/mnt/drbd" fstype=ext4
group TelephonyGroup ClusterIP fs_res MySQL Asterisk Apache
ms drbd_master_slave drbd_res \
meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
clone Cloned-Ping ClusterPing
location NoConnectionNode TelephonyGroup \
rule -inf: not_defined ping_net or ping_net lte 0
location PreferedNode TelephonyGroup 50: msa-tstasterisk1
order fs_after_drbd Mandatory: drbd_master_slave:promote TelephonyGroup:start
colocation fs_drbd_colo inf: TelephonyGroup drbd_master_slave:Master
property cib-bootstrap-options: \
dc-version=1.1.11-97629de \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes=2 \
stonith-enabled=false \
no-quorum-policy=ignore \
last-lrm-refresh=1466597871
В принципе, понимая что к чему на данную конфигурацию не так уж и страшно смотреть.
Текущее состояние кластера можно посмотреть выполнив команду `crm_mon -1` или просто `crm_mon`. Понятно, что не имеет значения, на каком узле выполняется данная команда кластера. Результат должен быть примерно следующим:
Online: [ msa-tstasterisk1 msa-tstasterisk2 ]
Master/Slave Set: drbd_master_slave [drbd_res]
Masters: [ msa-tstasterisk1 ]
Slaves: [ msa-tstasterisk2 ]
Clone Set: Cloned-Ping [ClusterPing]
Started: [ msa-tstasterisk1 msa-tstasterisk2 ]
Resource Group: TelephonyGroup
ClusterIP (ocf::heartbeat:IPaddr2): Started msa-tstasterisk1
fs_res (ocf::heartbeat:Filesystem): Started msa-tstasterisk1
MySQL (lsb:mysqld): Started msa-tstasterisk1
Asterisk (lsb:asterisk): Started msa-tstasterisk1
Apache (lsb:httpd): Started msa-tstasterisk1
Выгрузка сервисов
Все LSB ресурсы, которые у нас прописаны в менеджере ресурсов pacemaker, должны быть исключены из автозагрузки. Конечно, это не касается сервиса DRBD, т.к. он описан OCF ресурсом, а сам сервис должен быть запущен одновременно на двух узлах для физической синхронизации данных.
Необходимо выполнить выгрузку сервисов на двух узлах:
chkconfig asterisk off chkconfig httpd off chkconfig mysqld off chkconfig drbd on chkconfig corosync on chkconfig pacemaker on
Работа с кластером
Правка конфига
crm (live)> configure (live)configure> edit правим конфиг, выходим, сохраняя изменения (live)configure> verify если всё ок, то (live)configure> commit
Ссылки по теме
- https://geekpeek.net/linux-cluster-corosync-pacemaker/
- https://www.justinsilver.com/technology/linux/install-crmsh-centos-6/
- https://habrahabr.ru/post/108833/
- Список ресурсов OCF: http://www.linux-ha.org/wiki/Resource_agents
- Пример использования ping и location: https://habrahabr.ru/post/118925/
- Примеры описания размещения ресурсов на основе данных ping http://clusterlabs.org/pacemaker/doc/deprecated/en-US/Pacemaker/1.1-plugin/html/Pacemaker_Explained/_moving_resources_due_to_connectivity_changes.html
- Проверка LSB скрипта на совместимость с кластерным ядром http://clusterlabs.org/pacemaker/doc/deprecated/en-US/Pacemaker/1.1-plugin/html/Pacemaker_Explained/ap-lsb.html
- Source IP кластера https://unix.stackexchange.com/questions/298697/ip-source-address-issues-with-pacemaker-virtual-ip
Наши клиенты


















